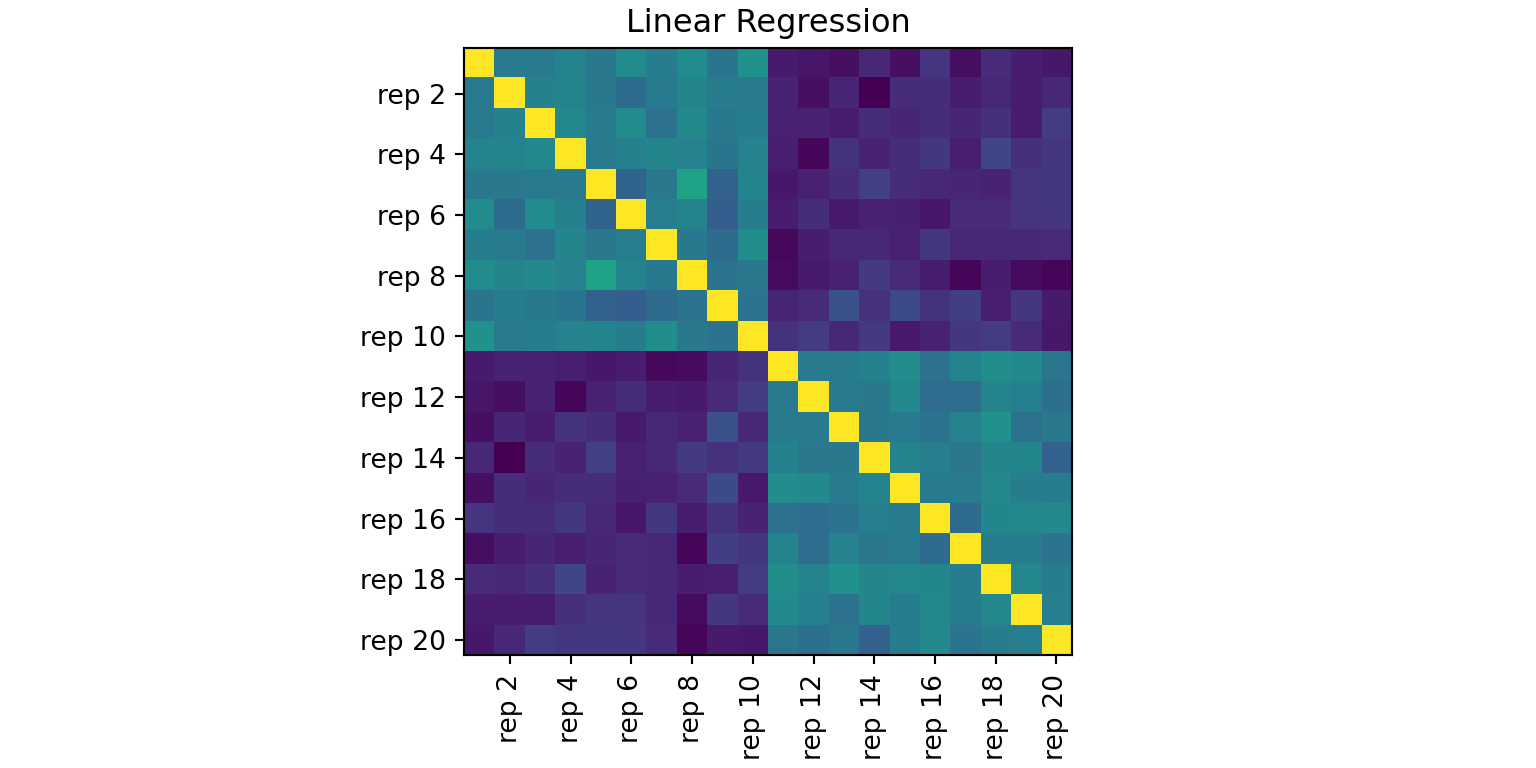
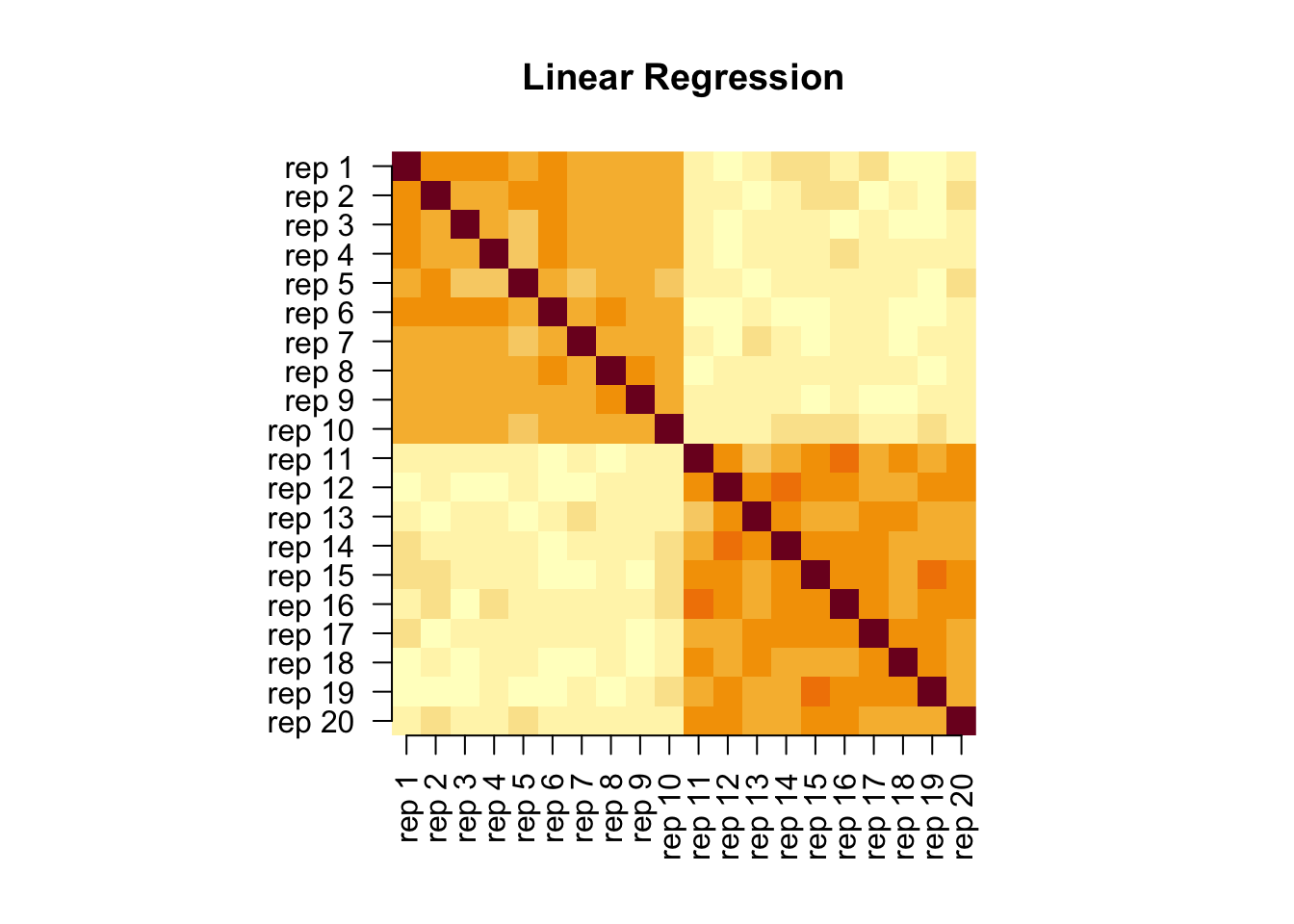
Compute pairwise linear-regression fit between multiple representations (Kornblith et al. 2019). After centering, for each pair, a least-squares map is used to assess how well one representation predicts the other, and the result is symmetrized.
mats: sequence of array-like, length \(M\) List or tuple of M data representations, each of shape (n_samples, n_features_k). All matrices must share the same number of rows for matching samples. Each element can be a NumPy array or any object convertible to one via numpy.asarray.
mats: A list of length M containing data matrices of size (n_samples, n_features_k). All matrices must share the same number of rows for matching samples.
# | cache: true# load necessary packagesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.preprocessing import StandardScalerimport repsim# set a random seednp.random.seed(1)# prepare the prototypeiris = load_iris(as_frame=True).frame.iloc[:, :4]url ="https://vincentarelbundock.github.io/Rdatasets/csv/datasets/USArrests.csv"usarrests = pd.read_csv(url, index_col=0)X = StandardScaler().fit_transform(iris.sample(50, random_state=1))Y = StandardScaler().fit_transform(usarrests)n, p_X, p_Y = X.shape[0], X.shape[1], Y.shape[1]# generate 10 of each by perturbationmats = []for _ inrange(10): mats.append(X + np.random.normal(scale=1.0, size=(n, p_X)))for _ inrange(10): mats.append(Y + np.random.normal(scale=1.0, size=(n, p_Y)))# compute similaritiesout_R2 = repsim.pwcca(mats)# visualizefig, ax = plt.subplots(figsize=(8, 4), constrained_layout=True)labs = [f"rep {i}"for i inrange(1, 21)]even_idx =list(range(1, 20, 2))im = ax.imshow(out_R2, origin="upper")ax.set_title("Linear Regression")
Text(0.5, 1.0, 'Linear Regression')
_ = ax.set_xticks(even_idx)_ = ax.set_xticklabels([labs[i] for i in even_idx], rotation=90)_ = ax.set_yticks(even_idx)_ = ax.set_yticklabels([labs[i] for i in even_idx])plt.show()
# load necessary packageslibrary(repsim)# set a random seedset.seed(1)# prepare the prototypeX <-as.matrix(scale(as.matrix(iris[sample(1:150, 50, replace =FALSE), 1:4])))Y <-as.matrix(scale(as.matrix(USArrests)))n <-nrow(X)p_X <-ncol(X)p_Y <-ncol(Y)# generate 10 of each by perturbationmats <-vector("list", length =20L)for (i in1:10){ mats[[i]] <- X +matrix(rnorm(n * p_X, sd =1), nrow = n)}for (j in11:20){ mats[[j]] <- Y +matrix(rnorm(n * p_Y, sd =1), nrow = n)}# compute similaritiesout_R2 <-pwcca(mats)# visualize: two heatmaps side by sidelabs <-paste0("rep ", 1:20)par(pty ="s")image(out_R2[, 20:1], axes =FALSE, main ="Linear Regression")axis(1, seq(0, 1, length.out =20), labels = labs, las =2)axis(2, at =seq(0, 1, length.out =20), labels =rev(labs), las =2)
References
Kornblith, Simon, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. “Similarity of Neural Network Representations Revisited.” In International Conference on Machine Learning, 3519–29. PMLR.